# Training Email Search Agent with RL using AgentScope-Tuner
This example demonstrates how to implement reinforcement fine-tuning for the Email Search task (inspired by [ART](https://openpipe.ai/blog/art-e-mail-agent)) using AgentScope-Tuner, whose RFT functionality is backed by [Trinity-RFT](https://github.com/agentscope-ai/Trinity-RFT).
## Task Setting
The agent's goal is to answer user queries by searching through an email inbox. The agent needs to:
- Understand the user's question
- Search for relevant emails using keywords
- Read email contents to extract information
- Provide accurate answers with proper source citations
**Agent Type**: The agent (`EmailSearchAgent`) extends `ReActAgent`, which follows a reasoning-acting loop to solve tasks iteratively.
**Environment**: The environment is a SQLite database containing emails from the Enron Email dataset. Each task provides:
- `question`: The user's email search query
- `inbox_address`: The email inbox to search
- `query_date`: The date context for the query
- `answer`: The expected answer (ground truth), only for reward calculation
- `message_ids`: IDs of relevant emails containing the answer, only for reward calculation
**Available Tools**:
- `search_emails`: Find emails by keywords, inbox address, and date range. Returns a list of email summaries (message_id and snippet).
- `read_email`: Read the full content of a specific email by message_id.
- `generate_response`: Provide the final structured answer with sources (inherited from ReAct agent).
## Dataset Preparation
The dataset contains email queries based on the [Enron Email dataset](https://huggingface.co/datasets/corbt/enron-emails). Run the data preparation script to generate the email database and datasets:
```bash
python prepare_data.py
```
If you want to choose a new database path, you can modify the `DEFAULT_DB_PATH` in [`prepare_data.py`](./prepare_data.py). Also, remember to set an environment variable `DEFAULT_EMAIL_DB_PATH` to point to the database path before moving to the next step:
```bash
export DEFAULT_EMAIL_DB_PATH=/path/to/enron_emails_dataset/data/enron_emails.db
```
This will create a SQLite database and datasets:
```
/path/to/enron_emails_dataset/
├── data
└── enron_emails.db # Email database
├── train.parquet # Training samples
└── test.parquet # Test samples
```
Each sample looks like:
```json
{
"id": 0,
"question": "Were there any variances detected for hour 6 on 3/9/01?",
"answer": "Yes, variances were detected in both Generation and Energy Import/Export schedules for hour 6 on 3/9/01.",
"message_ids": ["<17407857.1075840601283.JavaMail.evans@thyme>"],
"how_realistic": 0.800000011920929,
"inbox_address": "pete.davis@enron.com",
"query_date": "2001-03-16"
}
```
## Code Implementation
This section provides a high-level overview of the code implementation. For detailed implementation, please refer to the source code.
### Agent Workflow
The workflow function `run_email_search_agent` implements the agent-environment interaction loop:
```python
async def run_email_search_agent(
task: Dict,
model: ChatModelBase,
auxiliary_models: Dict[str, ChatModelBase],
) -> WorkflowOutput:
# Parse task and create agent
agent = EmailSearchAgent(
name="email_search_agent",
sys_prompt=system_prompt,
model=model,
max_iters=max_turns,
)
# Run the agent with structured output
response = await agent.reply(
msg=Msg("user", question, role="user"),
structured_model=AnswerModel,
)
return WorkflowOutput(response=response)
```
The agent follows a ReAct pattern: it reasons about the task, calls tools to search and read emails, and finally generates a structured response containing the answer and source message IDs.
### Judge Function
The judge function `email_search_judge` implements reward calculation using LLM-as-a-Judge:
```python
async def email_search_judge(
task: Dict,
response: Msg,
auxiliary_models: Dict[str, ChatModelBase],
) -> JudgeOutput:
# Extract answer and sources from response
answer = answer_and_sources.get("answer")
sources = answer_and_sources.get("sources", [])
# Judge correctness using LLM-as-a-Judge
judge_model = auxiliary_models.get('judge') or list(auxiliary_models.values())[0]
judge_response = await judge_correctness(
answer, query, judge_model
)
# Calculate reward based on:
# - Answer correctness (accuracy: -1.0 to 1.0)
# - Source correctness (format: partial rewards)
# - Efficiency (bonus for fewer turns, correct sources)
result = {"accuracy": ..., "format": ...} # calculated based on judge_response
return JudgeOutput(
reward=sum(result.values()),
metrics=metrics,
)
```
The reward function considers:
- **Answer correctness**: Evaluated by LLM-as-a-Judge comparing the agent's answer with the ground truth
- **Source correctness**: Whether the agent cited the correct email message IDs
- **Efficiency**: Bonus rewards for finding/reading the correct email and taking fewer turns
See [`main.py`](./main.py) and [`email_search_agent.py`](./email_search_agent.py) for implementation details.
## How to Run
### Prerequisites
- At least 4 NVIDIA GPUs with CUDA 12.8 or newer
* Note: For the 30B Judge model, you need to use a GPU with at least 4080 memory; you can also run the model on multiple GPUs by using `tensor_parallel_size > 1` to reduce the memory usage (by default, `tensor_parallel_size=2`).
- Follow the Trinity-RFT [installation guide](https://agentscope-ai.github.io/Trinity-RFT/en/main/tutorial/trinity_installation.html) to install the latest version from source code
- Download the model checkpoint (example):
```bash
huggingface-cli download Qwen/Qwen3-4B-Instruct-2507
huggingface-cli download Qwen/Qwen3-30B-A3B-Instruct-2507 # judge model
```
### Configuration
Adjust the configuration file ([`config.yaml`](./config.yaml)) based on your hardware. Key configuration sections include:
- **TunerModelConfig**: Set `model_path` to your model checkpoint path
- **AlgorithmConfig**: Configure RL algorithm parameters (e.g., `multi_step_grpo`, learning rate, policy loss function)
- **DatasetConfig**: The dataset path is specified in `main.py` when creating the `DatasetConfig` object
- **Auxiliary Models**: Configure judge model settings for LLM-as-a-Judge
For full configuration details, see [Trinity-RFT Configuration Guide](https://agentscope-ai.github.io/Trinity-RFT/en/main/tutorial/trinity_configs.html).
### Start-Up Commands
1. Prepare the dataset:
```bash
python prepare_data.py
export DEFAULT_EMAIL_DB_PATH=/path/to/enron_emails_dataset/data/enron_emails.db
```
2. Set up a [Ray](https://github.com/ray-project/ray) cluster:
```bash
ray start --head
```
3. Run the training script:
```bash
python main.py
```
## Experimental Results
### Quantitative Results
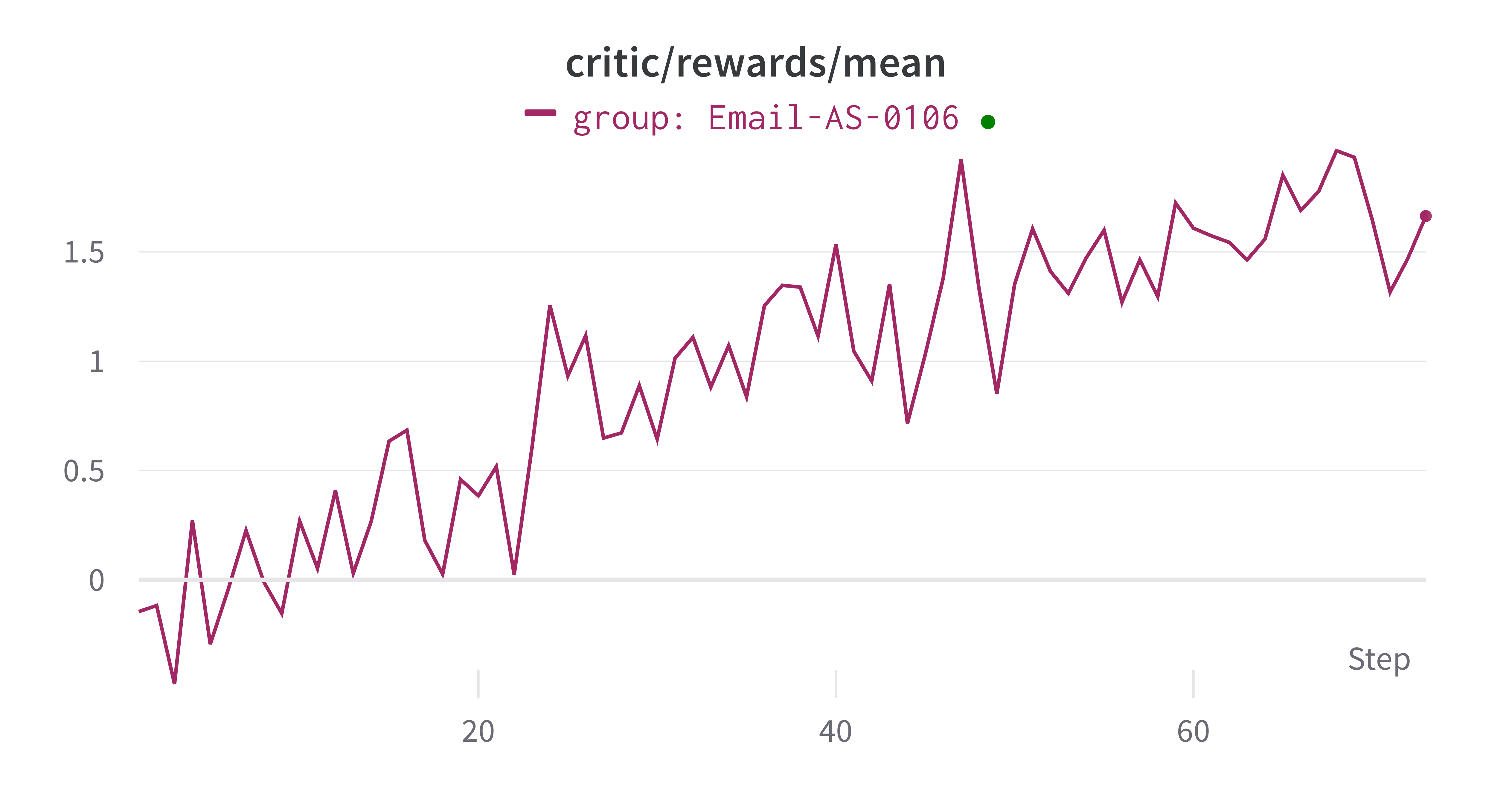
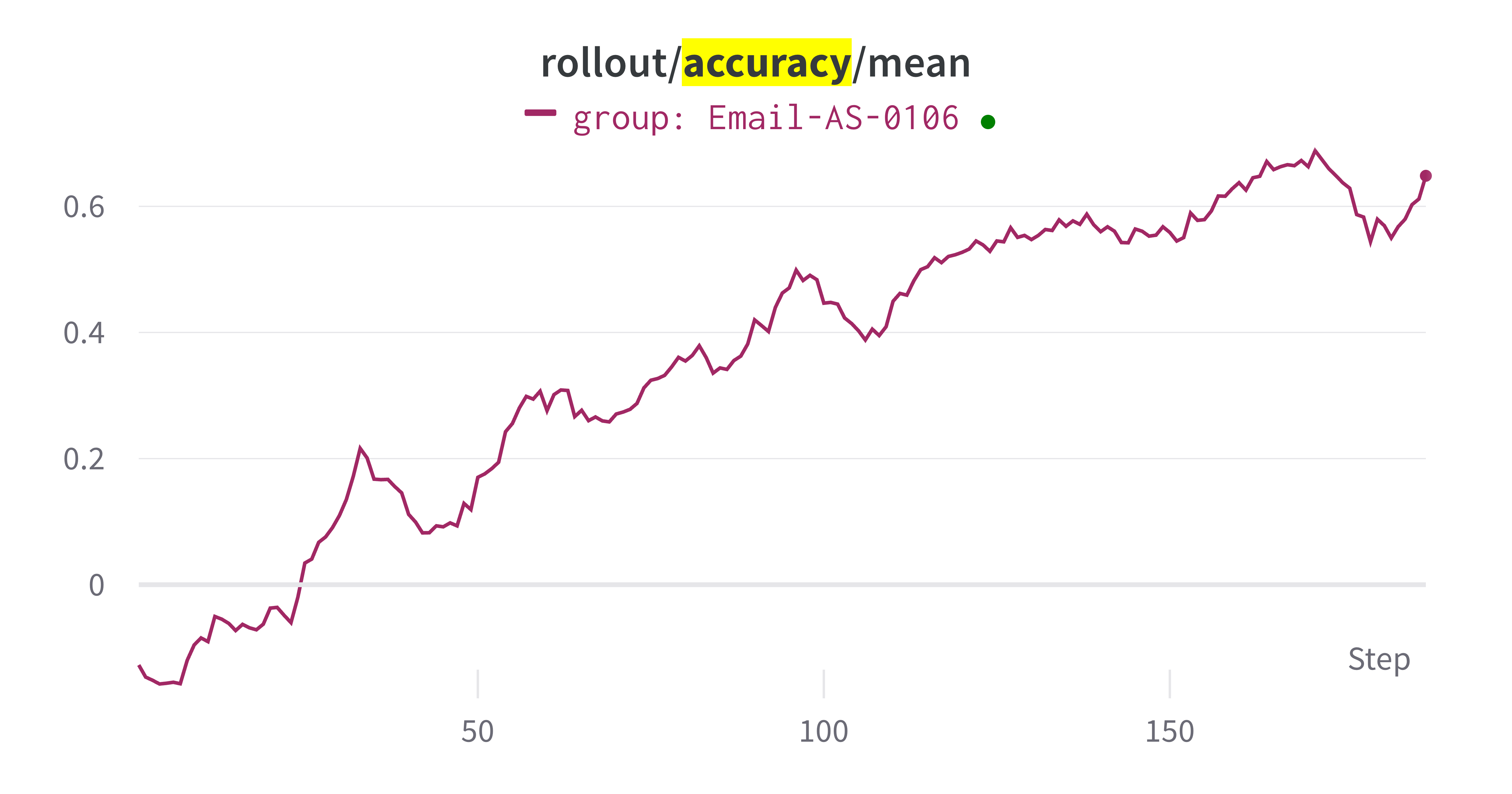
The training results show improvements in agent performance over training iterations. Key metrics include:
- **Train reward**: The average reward on training samples increases as the agent learns better strategies
- **Rollout accuracy**: The average accuracy on rollout samples increases as the agent learns better strategies
### Concrete Example
An example of the agent's behavior is shown below:
**Query:** "What do the color codes mean in the curve assessment?"
We show the last several turns of agent responses:
The agent performs multiple search attempts to find relevant emails. After some unsuccessful searches, the agent tries:
**Tool call:**
```json
{
"type": "tool_use",
"name": "search_emails",
"input": {
"inbox_address": "steven.kean@enron.com",
"query_date": "2001-04-03",
"keywords": ["curve", "assessment"]
}
}
```
**Tool result:**
```json
{
"type": "tool_result",
"name": "search_emails",
"output": [
{
"message_id": "<2654330.1075846153519.JavaMail.evans@thyme>",
"snippet": "... curves and Senior Management as necessary.\\n\\nCurve Assessment\\n Green: \\n - curve is reasonable\\n - small P&L ..."
},
{
"message_id": "<12499967.1075846153495.JavaMail.evans@thyme>",
"snippet": "... curves and Senior Management as necessary.\\n\\nCurve Assessment\\n Green: \\n - curve is reasonable\\n - small P&L ..."
}
]
}
```
After finding relevant emails, the agent uses `read_email` tool to read the full content of both emails:
**Tool call:**
```json
{
"type": "tool_use",
"name": "read_email",
"input": {
"message_id": "<2654330.1075846153519.JavaMail.evans@thyme>"
}
}
```
**Tool call:**
```json
{
"type": "tool_use",
"name": "read_email",
"input": {
"message_id": "<12499967.1075846153495.JavaMail.evans@thyme>"
}
}
```
After reading the emails, the agent generates the final structured response:
**Tool call:**
```json
{
"type": "tool_use",
"name": "generate_response",
"input": {
"answer": "In the curve assessment, the color codes are used as follows:\n- Green: The curve is considered reasonable, and the P&L (profit and loss) is small.",
"sources": [
"<2654330.1075846153519.JavaMail.evans@thyme>",
"<12499967.1075846153495.JavaMail.evans@thyme>"
]
}
}
```
The judge evaluates the answer as correct based on the ground truth.